从底层原理出发解决所有 Python 中文乱码(字符编码问题) |
您所在的位置:网站首页 › Python 处理字符串 › 从底层原理出发解决所有 Python 中文乱码(字符编码问题) |
从底层原理出发解决所有 Python 中文乱码(字符编码问题)
|
文章目录
前言先聊聊字符编码ASCII(American Standard Code for Information Interchange)UnicodeUTF-8(Unicode Transformation Format - 8-bit)UTF-16UTF-32
分析中文乱码、编码问题的原因常见案例案例一解决方案参考
案例二原因解决方案`Python2` 字符串的两种表现形式字节序列 和 Unicode 对象字节序列 和 Unicode 对象相互转换字符串运算`str(cell_data).decode("utf-8")` 写法的原因
案例三
总结个人简介
前言
最近偶尔会帮忙写一些爬虫代码,有一些需要使用 Python 编写,因此又拾起了很久没有写的 Python,让我无语的是总是遇到各种中文乱码的问题,所以趁着周末,总结一下遇到的中文乱码问题和对应的解决方案,以及为什么会出现中文乱码的问题。你可能遇到下列的各种问题:
1、SyntaxError: Non-ASCII character '\xe4' in file XXX
2、UnicodeDecodeError: 'ascii' codec can't decode byte 0xe8 in position 0: ordinal not in range(128)
3、......
先聊聊字符编码
当我们处理文本时,字符编码是一个关键的概念。字符编码是一种将字符映射到数字表示的方式。在计算机中,文本通常以数字的形式存储和处理,而字符编码就是定义这种映射关系的规则。在选择字符编码时,需要考虑存储空间、兼容性和处理效率等因素。UTF-8 目前是使用最广泛的字符编码,因为它在兼容性和节省空间方面都有良好的表现。下面对常用的编码做一个简单的介绍:
ASCII(American Standard Code for Information Interchange)
ASCII 是一种最早的字符编码,它使用 7 位二进制数字(0 到 127)表示常用的字符,包括字母、数字、标点符号和一些控制字符。由于只使用 7 位,ASCII 编码总共可以表示 128 个字符。
Unicode
为了解决 ASCII 编码的局限性,Unicode 应运而生。Unicode 是一个更为庞大的字符集,它包括世界上几乎所有的字符,符号和标点。每个字符都被分配一个唯一的数字,这个数字可能是 16 位(UCS-2)或者 32 位(UCS-4)。然而,Unicode 的缺点在于它需要更多的存储空间。
UTF-8(Unicode Transformation Format - 8-bit)
为了解决 Unicode 存储空间的问题,出现了 UTF-8 编码。UTF-8 使用不定长度的编码方案,能够根据字符的不同使用 1 到 4 个字节表示一个字符。它保留了与 ASCII 兼容的部分,因此可以在现有的 ASCII 系统中无缝使用,并且在表示非常用字符时能够更加节省空间。
UTF-16
UTF-16 是 Unicode 的一种实现方式,使用 16 位编码方案,每个字符使用 2 个字节表示。UTF-16 的一个特点是在表示一些非常用字符时可能会使用额外的一个或两个字节。
UTF-32
UTF-32 是 Unicode 的一种实现方式,使用 32 位编码方案,每个字符使用 4 个字节表示。UTF-32 的特点是每个字符都使用相同的固定长度,方便在字符串中进行随机访问。
分析中文乱码、编码问题的原因
从上面我们其实已经大概可以知道我们中文乱码、编码问题的罪魁祸首:编码方式不匹配。下面我将对一些常见的案例进行分析以及提供一些常见的解决方案。
常见案例
Python 版本 2.7
案例一
看一下下面两个例子:.py 文件的编码格式为UTF-8,Python2默认使用ASCII解码:
# 例一
s = "hello"
print s
// 正常执行
hello
# 例二
s = "你好"
print s
// 执行失败
SyntaxError: Non-ASCII character '\xe4' in file XXX
有些同学可能会比较疑惑,同样是编码格式不匹配,为什么例一可以正常执行,而例二执行失败。这是因为:UTF-8 是一种向后兼容的编码方式。如果文件中只包含 ASCII 字符,那么该文件符合 UTF-8 编码规范。这种特性使得使用 UTF-8 编码时,与使用 ASCII 编码的现有系统可以很好地协同工作。例一由于文件中只包含 ASCII 字符,即使使用 UTF-8 编码,编码结果和 ASCII 编码一致,当然也可以使用 ASCII 正常解码。
解决方案
指定文件的编码格式,让执行器使用指定的编码方式解析文件。
# coding=utf-8
s = "你好"
print s
// 正常执行
你好
参考
PEP 263 – Defining Python Source Code Encodings
案例二
我们看一下下面的代码:
# coding=utf-8
import xlwt
comment_list = [["标题", "序号"], [1, 2]]
code = "1234"
# Create a new workbook and add a sheet
workbook = xlwt.Workbook()
sheet = workbook.add_sheet('Sheet1')
for row_index, row_data in enumerate(comment_list):
for col_index, cell_data in enumerate(row_data):
sheet.write(row_index, col_index, cell_data)
workbook.save('./%s.xls' % code)
// 程序执行报错
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128)
'ascii' 无法解码字节 0xe6 (UTF-8中的中文字符)
// 如果写入的数据中没有中文数据是可以正常执行的
原因
// 我们看下这个对象的构造器:workbook = xlwt.Workbook() 可以看到默认使用的是 ascii 编码,而我们传入的数据是 UTF-8 (包含中文字符),因此无法解析
#################################################################
## Constructor
#################################################################
def __init__(self, encoding='ascii', style_compression=0):
self.encoding = encoding
self.__owner = 'None'
self.__country_code = None # 0x07 is Russia :-)
self.__wnd_protect = 0
self.__obj_protect = 0
解决方案
从上面我们已经知道是编码不一致的原因,因此我们只需要将Workbook编码调整为相同即可,比如调整为utf-8:
# coding=utf-8
import xlwt
comment_list = [["标题", "序号"], [1, 2]]
code = "1234"
# Create a new workbook and add a sheet
workbook = xlwt.Workbook(encoding="utf-8")
sheet = workbook.add_sheet('Sheet1')
for row_index, row_data in enumerate(comment_list):
for col_index, cell_data in enumerate(row_data):
sheet.write(row_index, col_index, cell_data)
workbook.save('./%s.xls' % code)
这里如果你不想用 utf-8 编码,你想用 gbk 编码怎么实现呢?其实中心思想是相同的,只要保证编码格式一致即可:
# coding=utf-8
import sys
import xlwt
comment_list = [["标题", "续保"], [1, 2]]
print "default encoding:", sys.getdefaultencoding()
# Create a new workbook and add a sheet
workbook = xlwt.Workbook(encoding="gbk")
sheet = workbook.add_sheet('Sheet1')
for row_index, row_data in enumerate(comment_list):
for col_index, cell_data in enumerate(row_data):
sheet.write(row_index, col_index, str(cell_data).decode("utf-8"))
code = "1234"
workbook.save('./%s.xls' % code)
// 程序执行正常
default encoding: ascii
Python2 字符串的两种表现形式
可能有朋友对上述案例中使用 gbk 方式中这段代码 str(cell_data).decode("utf-8") 有点疑惑,这其实涉及到 Python2 字符串的两种表现形式。
字节序列 和 Unicode 对象
在 Python 2 中,字符串类型被设计为字节序列而不是 Unicode 对象。这是 Python 2 与 Python 3 之间最重要的差异之一。在 Python 2 中,有两种主要的字符串类型:
1、str: 表示字节序列,是原始的字节串,而不涉及字符编码。
2、unicode: 表示 Unicode 字符串,用于处理字符编码和文本
示例:
# 在 Python 2 中,默认创建的是字节串而不是 Unicode 字符串
byte_str = "Hello, World!"
print type(byte_str) # 输出
# 创建 Unicode 字符串
unicode_str = u"你好"
print type(unicode_str) # 输出
字节序列 和 Unicode 对象相互转换
# 从 str 转换成 unicode
print byte_str.decode('utf-8')
# 从 unicode 转换成 str
print unicode_str.encode('utf-8')
有朋友也许很奇怪,为什么从 str 到 unicode 使用 decode,而 unicode 转换成 str 使用 encode,其实这是因为 Python 认为 16 位的 unicode 才是字符的唯一内码,而大家常用的字符集如 gb2312,gb18030/gbk,utf-8,以及 ascii 都是字符的二进制(字节)编码形式。因此从 unicode 到其它二进制编码格式都使用 encode。
字符串运算
在进行同时包含 str 与 unicode 的运算时,Python 一律都把 str 转换成 unicode 再运算,当然运算结果也是 unicode。
str(cell_data).decode("utf-8") 写法的原因
# 转换为 str 类型
str(cell_data)
# 这里为什么么需要先 decode("utf-8") 转为 unicode
# 实际上 Python 运行时并不知道 str 的编码,因此需要开发者指定正确的编码方式进行解码
# 如果开发者不指定编码方式进行手动解码则会使用 sys.getdefaultencoding() 配置的值 ascii 进行解码
str(cell_data).decode("utf-8")
# 由于我们在程序开头指定了编码方式为 utf-8 即 str 的编码格式,如果这样写:
sheet.write(row_index, col_index, cell_data)
程序执行异常:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128)
因为 ascii 编码无法解析带有中文的 utf-8 编码
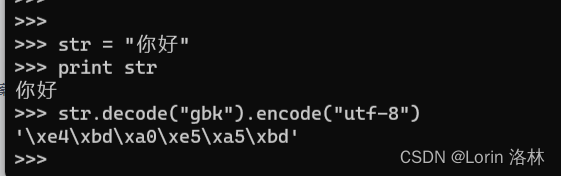
案例三
案例三我们来聊聊,有关控制台打印乱码的问题。
👋 你好,我是 Lorin 洛林,一位 Java 后端技术开发者!座右铭:Technology has the power to make the world a better place. 🚀 我对技术的热情是我不断学习和分享的动力。我的博客是一个关于Java生态系统、后端开发和最新技术趋势的地方。 🧠 作为一个 Java 后端技术爱好者,我不仅热衷于探索语言的新特性和技术的深度,还热衷于分享我的见解和最佳实践。我相信知识的分享和社区合作可以帮助我们共同成长。 💡 在我的博客上,你将找到关于Java核心概念、JVM 底层技术、常用框架如Spring和Mybatis 、MySQL等数据库管理、RabbitMQ、Rocketmq等消息中间件、性能优化等内容的深入文章。我也将分享一些编程技巧和解决问题的方法,以帮助你更好地掌握Java编程。 🌐 我鼓励互动和建立社区,因此请留下你的问题、建议或主题请求,让我知道你感兴趣的内容。此外,我将分享最新的互联网和技术资讯,以确保你与技术世界的最新发展保持联系。我期待与你一起在技术之路上前进,一起探讨技术世界的无限可能性。 📖 保持关注我的博客,让我们共同追求技术卓越。 |
【本文地址】
今日新闻 |
推荐新闻 |